转自:
很早以前收藏了一片文章:《》。最近刚好要做一些MongoDB方面的工作,于是翻出来温习了一下,用起来也确实挺方便。不过在使用过程中出现了一些个问题,加上更喜欢MongoUVE的操作习惯,于是决定“自己动手,丰衣足食”,写一个升级版的工具。
- 原版是用的WebForm开发的,新版打算升级到MVC
- 前端框架使用bootstrap
- Mongodb的驱动程序改为使用官方版的驱动程序
- 原版查询数据时使用的是解析sql语句的方式,新版打算采用javascript shell命令
- 原有的功能点都进行一些辅助性的改进
下面在对各个功能介绍的过程中,对升级的细节进行逐一的介绍,改动的地方会增加下划线进行标注。
系统主界面如下:
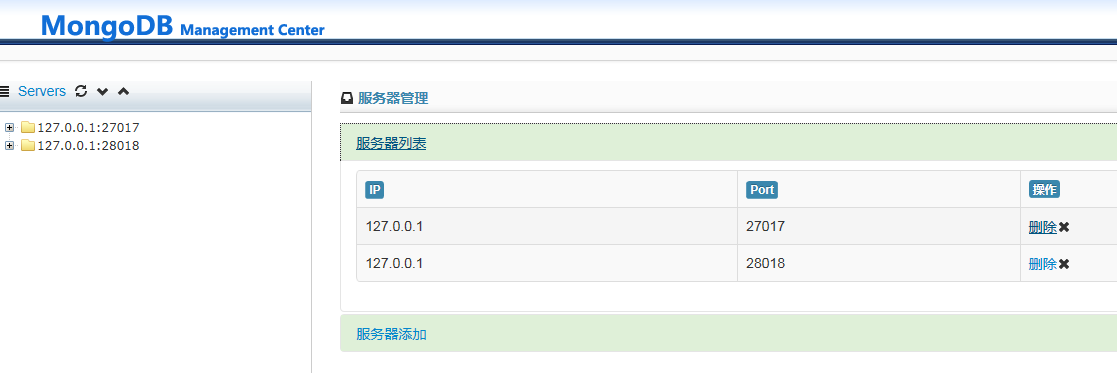
主界面采用了bootstrap的栅格系统进行布局:顶部为banner导航,左侧为Mongo对象的树菜单区域,右侧为功能操作的主区域。点击顶部banner和左侧上部的刷新图标均能重新加载主界面。主区域默认进入服务器管理的界面。
本例中,树菜单里的测试服务器有两个,是在本机通过不同端口建立的两个MongoDB实例,用来进行主从库的模拟(这个在后面会用到)。
首先,树菜单采用了zTree控件代替了原来的TreeView控件。zTree是一个非常好用的树控件,它支持json数据绑定,支持异步加载,对节点的控制和操作都非常强大,甚至可以直接在树节点上编辑数据。个人非常推荐这个控件。点击可以进入zTree控件的官网。
其次,Mongo对象的采用了“服务器 》数据库 》 数据表 》 字段和索引”的层次结构。因为字段和索引都处在表节点的下级,因此加入了两个虚拟节点【表信息】和【索引】来进行分类组织。并且点击不同的对象节点会触发不同的操作。
按照MongoUVE的表现形式,表节点右边增加了该表的数据总量的显示,字段节点右边增加了该字段的数据类型的显示。具体界面如下图:
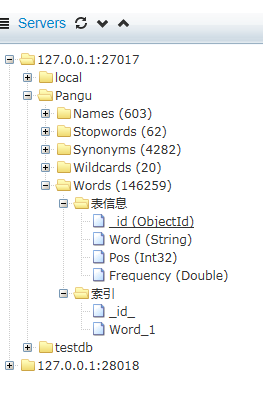
系统定义了树节点的数据结构:MongoTreeNode,用来生成绑定树控件的json数据。每个节点对应的对象类型也定义了对应的枚举:MongoTreeNodeType。代码如下:

////// 树节点 /// public class MongoTreeNode { ////// 唯一值 /// public uint ID { get; set; } ////// 父节点ID /// public uint PID { get; set; } ////// 名称 /// public string Name { get; set; } ////// 类型 /// public MongoTreeNodeType Type { get; set; } }////// 节点类型 /// public enum MongoTreeNodeType { ////// 服务器 /// [Description("服务器")] Server = 1, ////// 数据库 /// [Description("数据库")] Database = 2, ////// 数据表 /// [Description("数据表")] Collection = 3, ////// 字段 /// [Description("字段")] Field = 4, ////// 索引 /// [Description("索引")] Index =5, ////// 表信息填充节点 /// [Description("表信息填充节点")] TableFiller = 6, ////// 索引填充节点 /// [Description("索引填充节点")] IndexFiller = 7 }
zTree控件在绑定之前需要对各种属性进行预定义,详情请参考。在本系统中预制了ID和PID字段作为父子关系绑定的字段,而控件默认值是id和pId字段。
 View Code
View Code *注意:在实际使用的过程中,在调用树控件的绑定方法时,偶尔还会报“找不到绑定字段ID”的错,导致树控件无法显示。这个问题有待解决。
系统还定义了Mongo对象的数据结构,主要有“服务器、数据库、数据表 、字段和索引”五种(具体见代码)。对象的ID字段分别对应于树节点的ID和PID字段,即数据库对象的ID,既对应数据库节点的ID字段,又对应表节点的PID字段。对这些对象的结构定义,比原版系统精简了很多。
在读取数据表对象时,过滤了一些系统表和有特殊意义的表(如索引表,profile数据表)。如果需要放开显示的话,可以去程序中进行屏蔽。代码如下:
View Code 有一个改进是:对象ID字段的数据类型从原来的GUID改为uint类型(为了保证数值大于0,切避免出现正值和负值取绝对值后重复的可能性,才采用无符合数),以提高查找效率并减小json数据的大小。ID字段是由程序自动生成的唯一的随机值,它是在一个并行计算(之后会讲到)过程中得到的。为了保证在并行环境中随机数的唯一性,参考了《》这篇文章。最后形成的代码很简单,经过测试到目前为止还没有出现过ID值重复的情况。代码如下:
View Code Mongo对象和树节点是同一时间读取的,在第一次加载完后就会保存至缓存中,缓存时间为2小时。当缓存超时后再点击树菜单节点或进行其他操作时,在主区域都会出现如下的界面,要求重新加载数据:

上面提到的并行计算的方法,是在每次从数据库中加载数据时才会调用,这也是本次一大改进。通过采用并行计算,确实提高了读取数据的效率,数据库内对象越多越明显。关于并行计算的学习,我推荐《》这一系列的文章,非常好。新版系统的代码里保留了循环读取Mongo对象的代码,有兴趣的朋友,可以自己修改一下程序去体会一下并行和循环的差别。为了保证在并行计算中的线程安全,树节点采用HashSet进行缓存,HashSet本身是线程安全的;而Mongo对象则采用Hashtable进行缓存,在初始化时,需要使用Synchronized方法来保证线程安全。
View Code 服务器管理界面在初始加载时就会显示在主区域内。通过点击左侧顶部的【Servers】链接,也能操作服务器管理。主区域的操作界面,统一采用了bootstrap中的折叠插件来进行展示,点击不同的折叠栏,会显示该栏的内容同时折叠其他的内容。
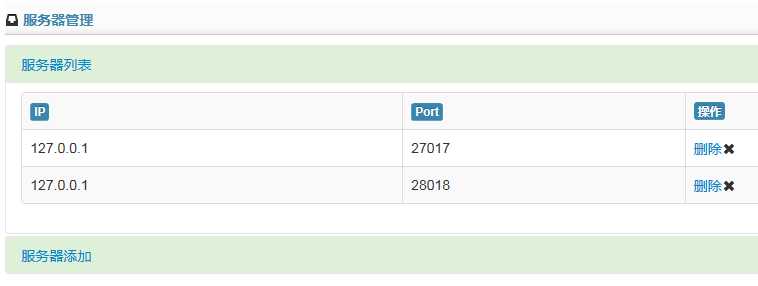
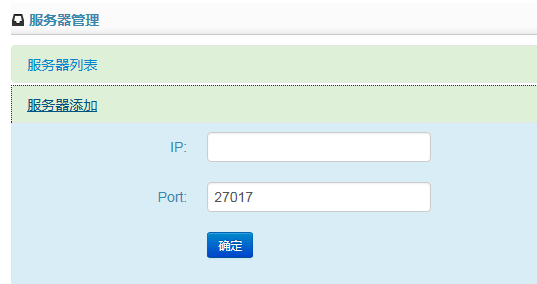
服务器管理功能,实质是修改程序里【Config\servers.config】的文件,为其添加或删除节点。文件里保存的数据,作为并行计算读取数据的起点。
点击树菜单中的服务器节点,就会在主区域内显示该服务器的统计信息。在主区域的顶部,会显示服务器对象的一些基本信息。本系统中,大量的信息展示均使用zTree控件进行展现,因此重用了MongoTreeNode的结构,不同的地方仅在于不需要为MongoTreeNodeType属性赋值。
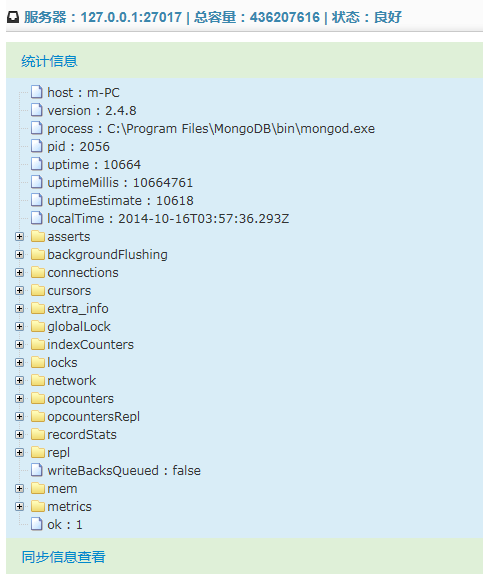
查看服务器的统计信息,实际对应于MongoDB的adminCommand命令:db.adminCommand{"serverStatus", 1}。新版系统实现如下:
View Code 这里简单介绍一下MongoDB的BsonDocument。详情请移步至官方文档: 。
BsonDocument是官方驱动进行各种操作的一个基础数据,它是一个键/值对的集合,有三种生成方式:
- 使用Add或者Set方法 View Code
- 使用Add或者Set的流式接口方法 View Code
- 使用C#的类初始化语法(推荐使用此种方法) View Code
基于BsonDocument派生出很多子类,包括:
- CommandDocument:用于运行命令的参数文档,在RunCommand方法中使用
- FieldsDocument:用于查询返回字段的参数文档,在SetFields方法中使用
- GroupByDocument:用于group的参数文档(这个的用处暂时没体会得到)
- QueryDocument:用于设置查询条件的参数文档,在Find方法中使用
- SortByDocument:用于设置排序规则的参数文档,在SetSortOrder方法中使用
- UpdateDocument:用于修改数据的参数文档,在Update方法中使用
其他子类和它们的具体使用方法,需要在使用过程中去体会。一般来说,什么样的类型就对应什么样的操作方法。在方法调用的参数接口说明中,都会有比较明显的标识。
在文章的第一节说明了在本机搭建有主从环境,其中127.0.0.1:27017是主服务器,其中127.0.0.1:28018是从服务器。通过点击【查看同步信息】链接,可以进入查看同步信息的页面。
主服务器信息:
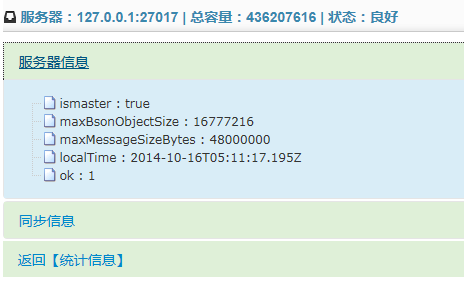
主服务器的同步日志,新版系统设定为仅显示10条记录,可以自己进行修改:

从服务器信息:
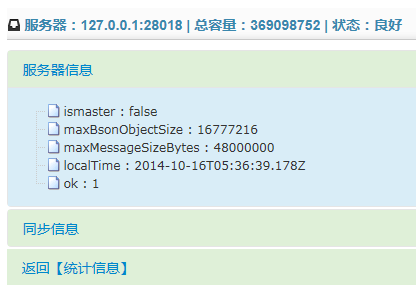
从服务器的源信息:
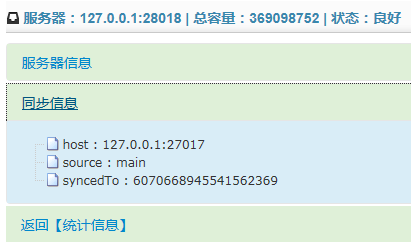
服务器的主从信息也都是使用adminCommand命令来获取。主服务器的同步日志则是从local库中的【oplog.$main】表中读取,从服务器的源信息则是从local库中的【sources】表读取。实现代码:
View Code 点击树菜单中的数据库节点,就会在主区域内显示该数据库的统计信息。在主区域的顶部,会显示数据库对象的一些基本信息。
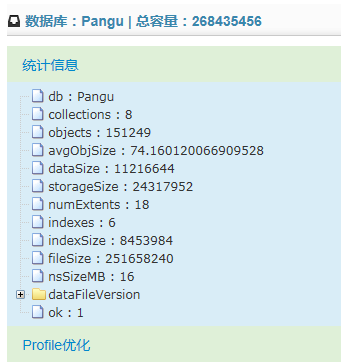
数据库的统计信息是使用RunCommand命令来获取,因为是查看某个具体数据库的统计信息,因此不需要使用Admin库,即不使用adminCommand。代码如下:
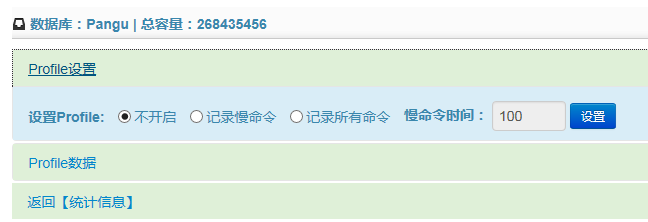
View Code 在数据库的统计信息页面点击【Profile优化】的链接,即进入数据库的Profile设置的界面。Profile的状态一共有三种:
- 不开启:即不记录pofile数据,这样就无法进行效率分析
- 记录慢命令:仅记录执行速度慢的profile数据,可以自行设置判断是否是慢命令的执行时间的临界值,一般推荐此种方式
- 记录所有命令:记录所有执行的profile数据,因为记录profile数据也需要系统资源和开销,因此不推荐开启记录所有命令的方式
查看Profile数据,可以自行调整显示的条数。官方驱动返回的数据类型是 SystemProfileInfo,大家可以查看源代码获得详细的信息。在本系统中选取了其中几个属性进行了一下转换,并采用更直观的列表形式来进行展示。
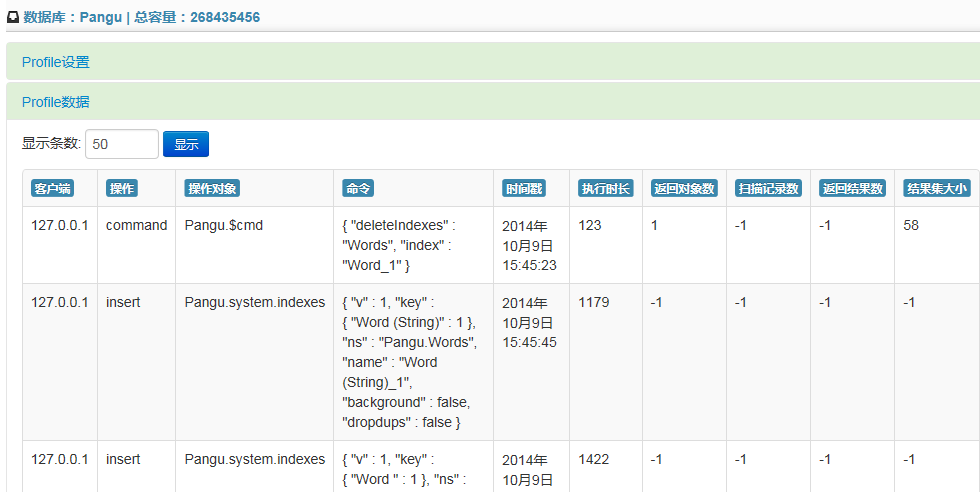
优化的一些小建议:
- 当【扫描记录数】远大于【返回记录数】,可以考虑通过增加索引来优化查询效率
- 当【返回结果集】过大,那么说明我们返回的结果集太大了,可以考虑只返回所需要的字段
- 如果写查询量或者update量过大的话,多加索引是会有好处的;执行 update 操作时同样检查一下【扫描记录数】,并使用索引减少文档扫描数量
- 如果读操作很少,那么尽量不要添加索引,因为索引越多,写操作会越慢;如果读操作很多,则需要考虑创建合适的索引
点击树菜单中的数据表节点,就会在主区域内显示该数据表的统计信息。在主区域的顶部,会显示数据表对象的一些基本信息。
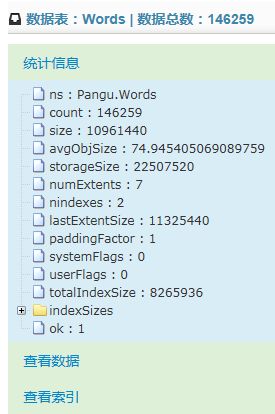
数据表的统计信息是使用RunCommand命令来获取,需要在某个具体的数据库上执行该命令,并需要传入对应表的名称。代码如下:
View Code 在数据表统计信息的页面点击【查看数据】链接,或者是点击树菜单中的【表信息】节点,均可以进入数据查看页面。注意:【表信息】的子节点是字段节点,点此节点不做任何操作。
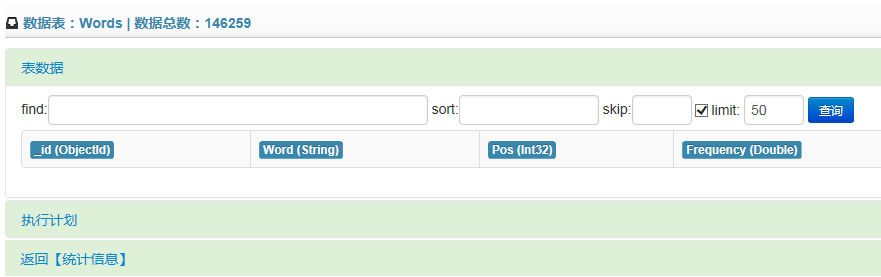
数据查询的操作方式抛弃了原版系统解析sql语句的方式,采用了类似MongoUVE的操作形式,输入json格式的命令进行查询。新版系统可设置【find、sort、skip、limit】的参数。查询结果采用列表方式展示,表头内显示字段名以及该字段的数据类型。在显示数据时,当数据为BsonDocument类型时,做了序列化字符串的处理。
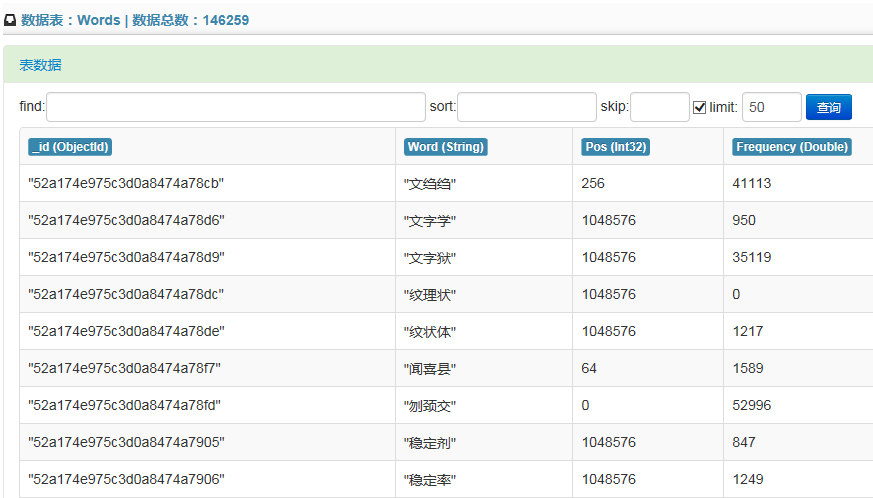
在实现利用javascript shell命令进行查询时,差点绕了一个大圈子:一开始觉得需要做一个javascript shell命令解析器,再配合MongoDB.Driver.Builders.Query类来生成查询用的QueryDocument。一开始做了一个or命令的解析,例如:{$or:[{Word:'汶川县'},{Pos:{$gt:256}}]},觉得太难了,各种嵌套怎么解析得完?官方驱动怎么可能对javascript shell命令的支持这么差?于是开始翻源代码,突然看到一个方法:BsonDocument.Parse!!然后一切都容易了。查询实现的方法如下:
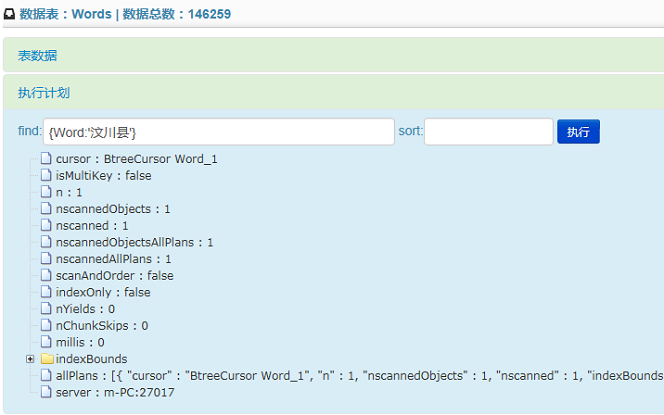
View Code 新版系统增加了查看执行计划的功能。在此可对查询语句的执行效率进行分析,从而协助进行系统优化。目前仅支持【find、sort】的参数设定。

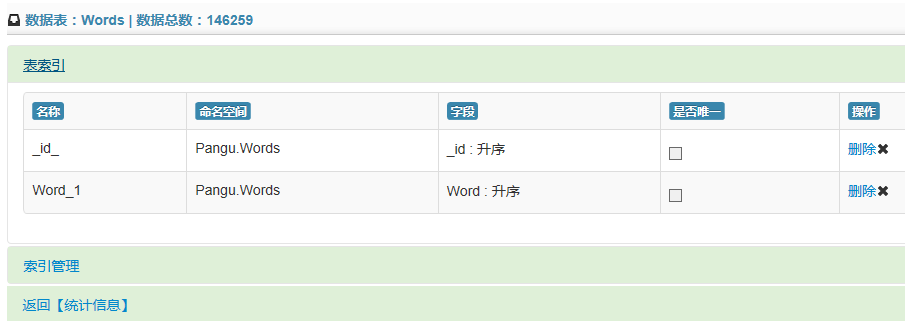
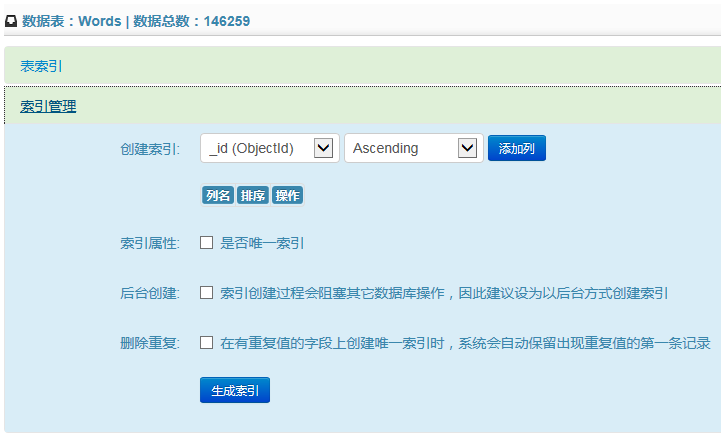
在数据表统计信息的页面点击【查看索引】链接,或者是点击树菜单中的【索引】节点,可进入索引管理页面。该页面提供索引列表展示,删除索引以及添加索引的功能。注意:【索引】的子节点是索引节点,点此节点不做任何操作。
新增索引时,可以使用多个字段生成组合索引。目前不支持当某个字段为文档类型时,使用内部字段设置索引的情况。另外索引在创建时的一些选项的意义也做了相应的说明。
对于这个新版系统上面介绍了很多,目前还缺少一部分的功能,例如数据的新增和修改的操作;Mapreduce的支持;甚至自定义javascript shell命令的执行(类似执行自定义的sql语句)等……欠缺的功能以后有时间再慢慢补上来的。
在介绍的过程中也穿插的展示了一部分代码,但没有对系统的代码进行完整的介绍,理由是整套代码几乎没有难度,况且代码就是最好的文档,而整个系统的代码量并不大。开发过程主要是加深对MongoDB的一些概念的认识,再配合官方驱动的各种方法进行佐证。
那么,最后,问题来了……代码在哪里呢?中国XX找XX吗?当然不是,代码下载请点下图:
Difficulty of making decision depends on what to lose not gain